Skills Is All You Need.
The title is a joke on “Attention Is All You Need” which gave us the architecture shift. “Skills is all you need” is the version of the same kind of provocation for agent systems.
I have recently been SKILL PILLED!

And like most good provocations, it is wrong in the useful way.
Skills are not literally all you need. But paired with current frontier models, they now get you much further than most workflow stacks want to admit. A lot of what teams still describe as “agent orchestration” is becoming a thinner layer of runtime context, tool access, and evaluation. The specialisation is no longer only in training. It is increasingly in the skill.
Client-side use is already proven. If you have used Claude Desktop, Codex, or a serious coding agent, you already know skills can improve behaviour inside a local loop. The more interesting shift now is that the same pattern is becoming viable on the backend, where the skill is no longer just helping a user in a session but driving real work behind a runtime boundary.
That matters because it changes where the engineering effort goes.
In late 2025 + early 2026, several things lined up with the increased model intelligence, that make the shift harder to dismiss. Anthropic’s skill-creator picked up an eval-centric workflow. OpenAI published practical guidance for testing skills using JSON traces, deterministic checks, and rubric-based grading. At roughly the same moment, LangChain’s deepagents repo made the harness language explicit: planning, filesystem access, and subagents as reusable machinery for more capable agents.
That combination is the real story. Skills got more useful because the models got better, but also because the surrounding tooling got serious enough to treat skills as software. Markdown is also the programming language paired with scripts. That matters most on the backend, where evaluation, access control, tracing, and deployment turn a clever prompt pattern into an actual system.
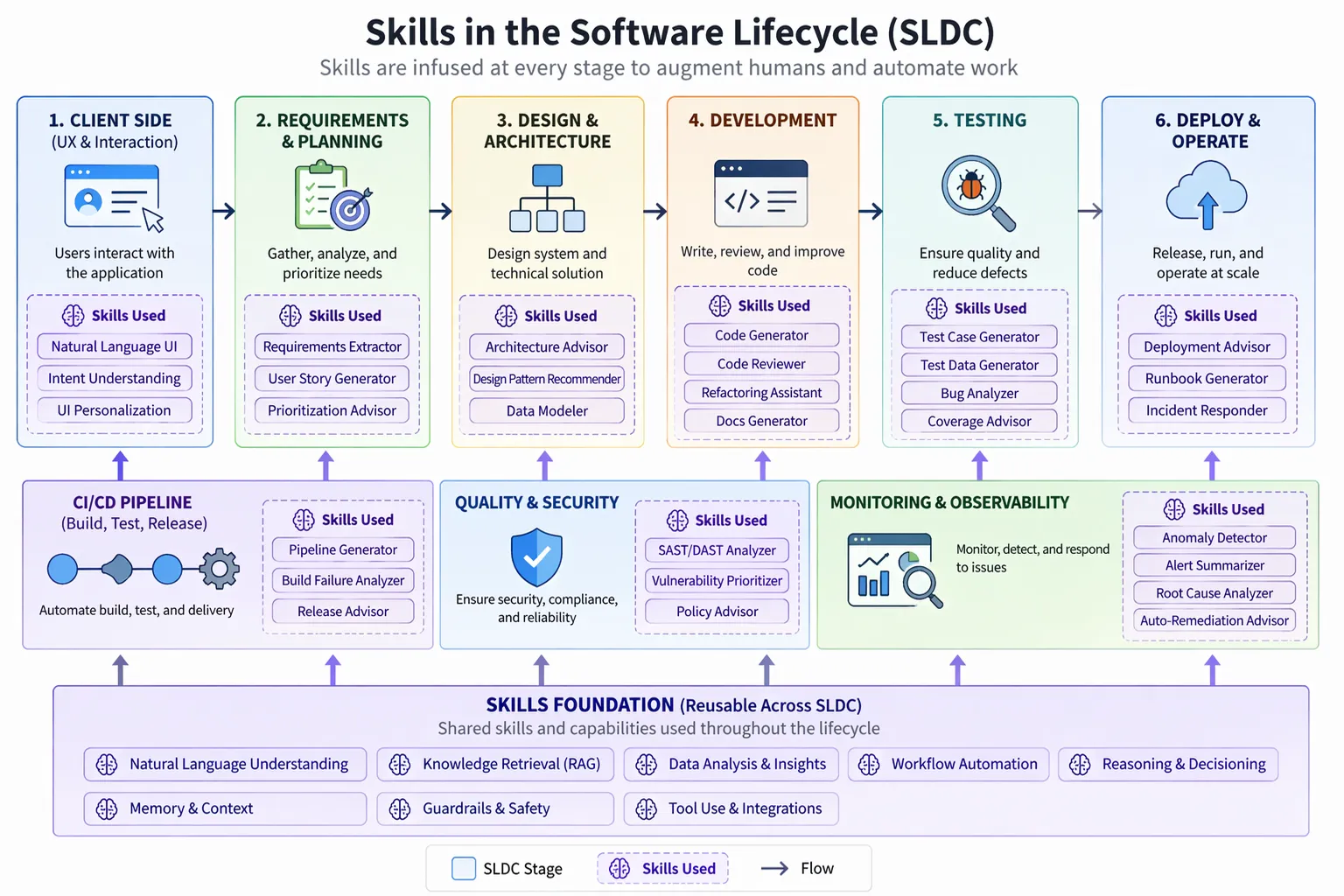
Skills are eating workflow code, and the backend is the interesting part
The fastest way to understand the shift is this: skills are becoming a runtime specialisation layer.
That is different from fine-tuning, and it is different from the old “just prompt it harder” era. A good skill is not just a paragraph of instructions. It is a reusable unit of operational context:
- when to trigger
- what tools to use
- what success looks like
- what failure modes to watch for
- how to validate the result
Once you pair that with a strong reasoning or coding tuned model, the amount of bespoke workflow code you still need drops fast.
You can feel this in earlier versions of coding agents first because the feedback loop is brutally short and required human guidance. Give a frontier model a good skill, a filesystem, CLI access, and a few tools. It can plan, inspect, revise, and validate in one session. What previously looked like a mini product made of hand-built state transitions often collapses into a much smaller harness plus a tested skill.
That client-side win is real, but it is no longer the surprising part. We already know a skill can improve a local coding agent, desktop workflow, or operator-facing assistant. The more important shift is that the same skill can now sit behind a service boundary and drive backend tasks with controlled tool access, auditability, and evals.
Reaching for fine-tuning often is not required. They do not actually need the model weights to change. They need a reliable way to inject domain procedure, tool usage rules, and evaluation criteria at runtime. Its not just about convenience, it changes iteration speed. If the business logic changes next week, you update the skill, the rubrics, the eval set, or the tool policy. You do not kick off a retraining pipeline and hope the new checkpoint behaves. In most cases i leave that to the foundational model builders, the rate of improvement will likely outpace my fine tuning process.
Evals have made complex skills credible
The part that changed my mind is not the skill format itself. It is the eval loop around it.
Anthropic’s updated skill-creator flow, is a useful signal because it treats a skill like something that can be created, evaluated, improved, and benchmarked. Not admired. Not vaguely “prompt engineered.” Tested.
That distinction matters.
Claude Code eval loop gets to the same point from the builder’s side. The interesting part is not that you can write a better description. It is that you can run the skill against realistic prompts, inspect where it failed, improve the description, and loop. The skill becomes an artefact with failure cases and regressions, not a static note in a repo.
OpenAI’s eval-skills guidance sharpens this further. Pushes a very practical pattern:
- run the agent with structured trace output
- save the JSON trace
- score what it actually did
- then add rubric-based grading for the qualitative parts
Rather than judging an agent system by whether the final answer sounds polished. That is not enough. For complex workflows, the output is only half the story. You also need to know:
- which tools it called
- whether it called them in the right order
- whether it skipped a mandatory validation step
- whether it drifted into a pointless loop
- whether it pulled in the wrong source or touched the wrong data
Once you evaluate the trajectory, not just the prose, skills stop looking like prompt decoration and start looking like a maintainable workflow layer.
The harness is where the real complexity lives
This is where the “skills is all you need” slogan breaks.
The skill is important, but the harness & model is still the core.
The harness decides which skill activates, what tools are exposed, what gets logged, which rubrics run, when the agent is allowed to retry, and where the execution boundary sits. That is where you handle governance, cost, privacy, secrets, and traceability. That is also where you decide whether the agent is doing controlled work or just freewheeling.
This is why deepagents is interesting. The LangChain team is not pretending the model alone is enough. They are packaging the supporting machinery: planning, filesystem access, subagents, middleware, and human review points. That is the right mental model. Skills are the specialisation layer, but the harness is the control plane.
If you care about enterprise use cases, the trajectory matters as much as the answer. I want to see the tool calls. I want to see the retries. I want to see which branch of the task plan was taken. I want to know what evidence the system used before it made a claim. That is the difference between a cool demo and something I can actually put in front of a business user.
The good news is that modern runtimes are starting to expose those signals. AWS AgentCore’s observability guidance, for example, explicitly talks about enabling tracing for runtime resources and pushing spans into logs. That is exactly the kind of operational plumbing you need if the valuable part of the system is no longer a fixed workflow DAG but a model-guided trajectory through tools and context.
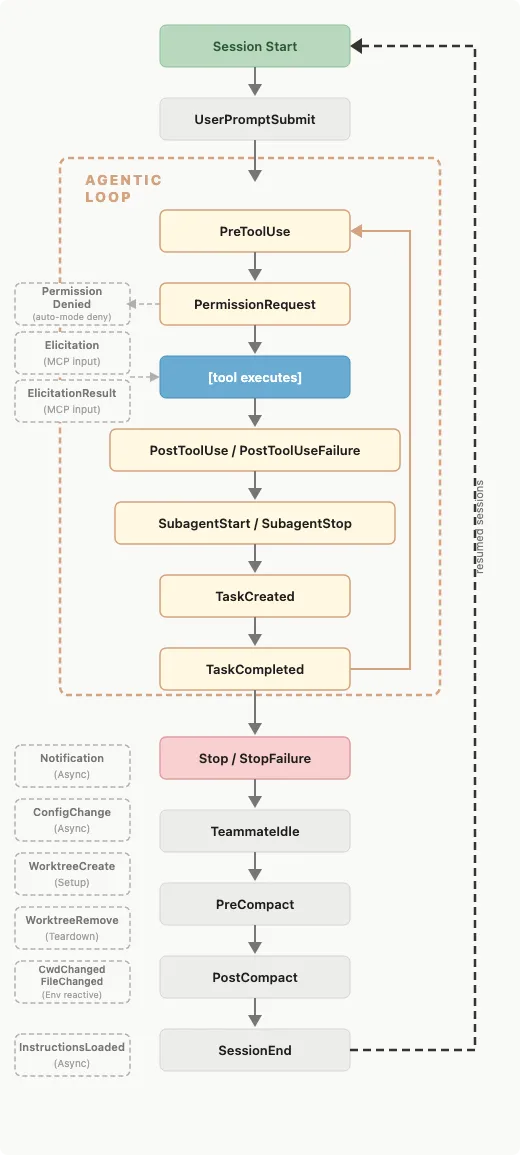
Claude hooks also expose the shift here enabling harness tracing itself. Claude Code’s hooks now give you lifecycle points across the agent loop like PreToolUse, PostToolUse, SubagentStart, SubagentStop, TaskCreated, TaskCompleted, and Stop, which is exactly the shape you need if you want to inspect the trajectory rather than just the final answer. Pair that with something like phoenix-claude-code, which routes Claude activity into Phoenix for trace capture, tool spans, and later eval analysis, and the harness starts to become inspectable infrastructure rather than a black box. Once you can trace the harness, replay failures, and judge the behaviour of the loop itself, you can finally improve the workflow with something more rigorous than vibe checks.
TRACES —> MONITOR —> ANNOTATE —> JUDGE —> DATASET —> CI —> IMPROVE —> repeat
From local POC to real backend
One reason this moment feels different is that the path from local prototype to backend system has become short.
You can now build a proof of concept directly in Claude Desktop or ChatGPT/Codex-style environments, connect it to MCP servers, use internal CLI tools as data connectors, chain skills together, and see very quickly whether the skill changes behaviour in a useful way. That used to require much more scaffolding.
That client-side prototyping loop matters because it gives you a fast place to discover the workflow. But if the workflow is valuable, the destination is usually not the client. The destination is a backend runtime where the skill can access the right systems, run inside policy boundaries, and be observed like the rest of your application stack.
Now you add the connections, use the skill creator to describe the workflow, run an iteration, use another skill to evaluate the outcome, improve the skill, and then deploy it.
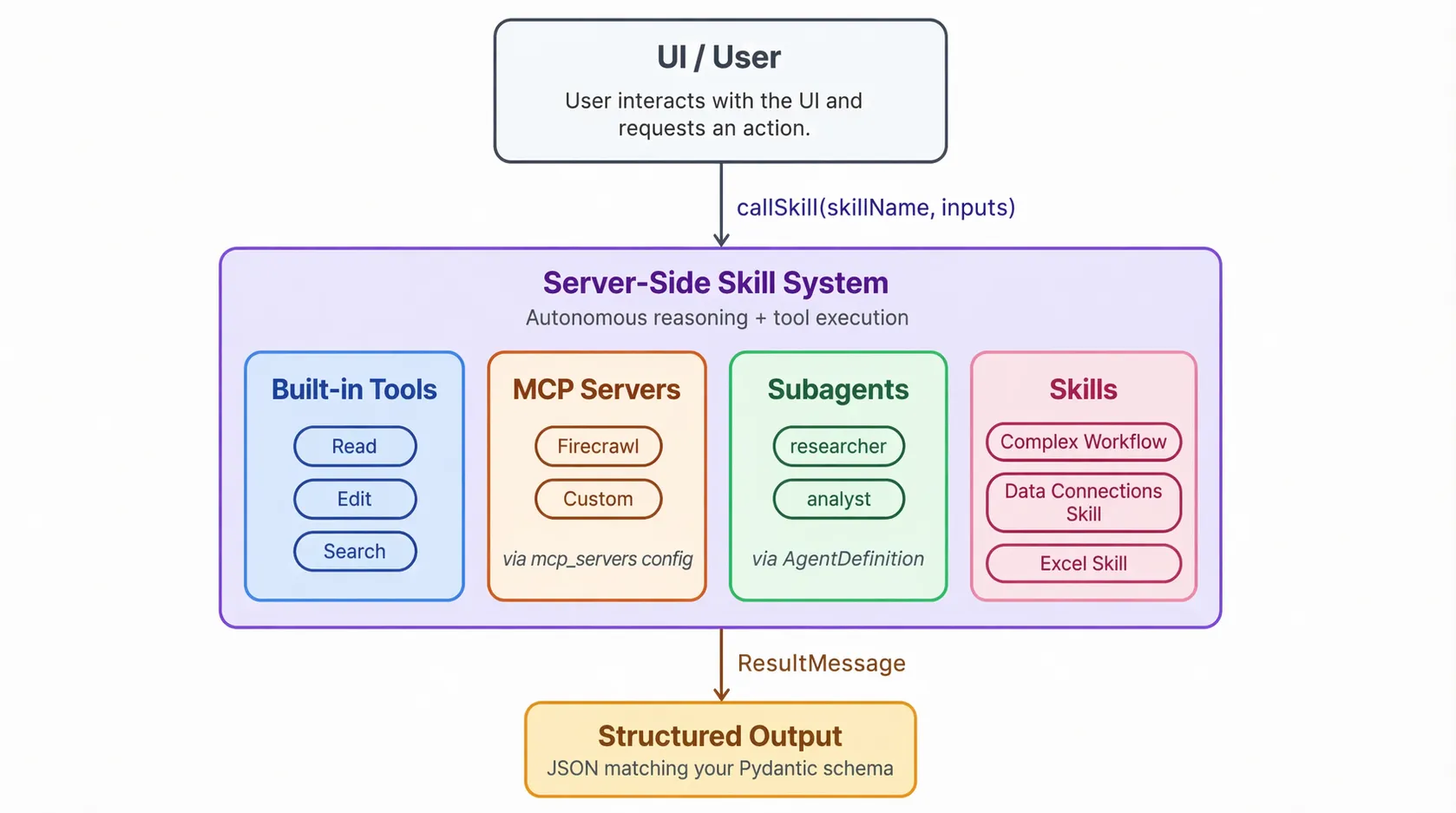
For internal IP-heavy use cases, this is a big deal. A team can start with:
- a skill that captures the domain procedure
- MCP connectors for the relevant systems
- CLI tools for the awkward edge cases
- a small eval set based on real prompts
- a rubric for what “good” looks like
That is enough to learn something real.
If the workflow touches sensitive data or proprietary process, you do not need to abandon the approach. You move the same pattern behind a runtime boundary. Put the skill in a sandboxed execution environment. Restrict the tool surface. Trace the execution. Version the skill. Keep the evals close. The skill does not need to stay trapped inside a desktop app to be useful. It can run as a server-side skill.
This is where a lot of the IP-heavy opportunities sit. Not in training a bespoke model from scratch, but in encoding the organisation’s way of working, exposing only the right tools, and evaluating the result continuously. That is why I think skills are becoming a serious backend pattern rather than just a nice client-side convenience.
What skills still do not replace
There are still limits, and they matter.
Skills do not remove the need for system design. They do not solve poor data quality. They do not make evaluation optional. They do not magically turn a weak model into a domain expert. And they definitely do not erase the need for carefully chosen runtime boundaries if you are operating in regulated or high-risk environments. They also do not replace coded backends in every case. Sometimes you start with a skill, learn the shape of the workflow, and then harden parts of it into conventional backend code. The point is that the skill gives you a much faster way to find the shape of the thing.
Warning: This may not be the most cost-efficient way to run your workflow, but it is a very good way to iterate fast.
The more common path now looks like this: start with a strong base model, add a tested skill, wire in the right tools, record the trajectory, and keep improving the eval set until the system is boringly reliable for the use case you care about.
That is not “just prompting.” It is a real engineering discipline.
Deployment is where skills become a product
The part I would not underestimate now is deployment.
Getting a skill to work locally in Claude Desktop or Codex is useful, but it is still only proof that the workflow has potential. We already know skills help on the client side. The real transition happens when you move the skill behind a backend and make it run in a controlled environment with the right tools, credentials, and traces.
For IP-heavy workflows, I think the better pattern is increasingly:
- keep the skill as the specialisation layer
- run the agent server-side inside a sandboxed VM or isolated runtime
- expose only the MCP connectors and CLI tools the workflow actually needs
- capture the trajectory so you can replay failures and grade behaviour, not just outputs
This is also why I do not think skills are just fancy markdown. Once they can be evaluated locally, lifted into a LangGraph deep-agents or Claude Agent SDK style harness, and then deployed into a sandbox runtime, they start looking a lot more like application logic. The client side proved the interface. The backend is where the pattern becomes markdown as software.