Preparing Deep Research for enterprise

A couple of common asks for Deep research in the enterprise “Use Deep Research to gather company information to generate a report” or “Use Deep Research to grab all the latest financial statements of a company and synthesis”. You will often find some reports have hidden, needle in the haystack inaccuracies. This is a typical enterprise story, powerful research agents plus weak source data and context discipline, leads to accuracy failures. The root cause is not the agentic web search loop (identifying knowledge gaps on the collected data and keep iterating) per se; it’s unclear context, and missing guardrails and controls around data, missing domain expertise in decision making and actions.
Imagine you hand an agent, a tricky research brief like;
“assess competitor X’s patent exposure and summarise regulatory risks.”
You want a short, defensible report that you trust with sources, and a clear trail showing how the agent decided what to include and when to stop searching. If you’re building enterprise grade research tooling, quality assurance and evaluation control flow are the key part to the product and the part that makes the system trustworthy.
In my experience building and testing deep research agents, I now think about the QA/eval pipeline as the product, not an afterthought.
Practical recommendations for implementing Deep Research in the enterprise.
The core functionality that makes or breaks an enterprise Deep Research service. At the baseline, a Deep Research agent tech stack needs three core technical ingredients to be useful for an enterprise: Organised knowledge data source that you can control, an orchestration layer that records what the agent did and prevents internal data leakage, and quality assurance steps to evaluate and control the domain flow while guarding against inaccuracies. While it is possible to have an internal data only deep research agent or a combined internal/external data sources, i will focus on an agent that only gathers external web content to minimise complexity for now.
Ingredient 1: Knowledge base: External Web
The selection of a web search provider is a key strategic decision. Its something we might take for granted using GPT style chat bots and their ability to search the web to bring in the right context.
- For your enterprise you need to pick the right provider to protect your internal searches against tracking and data leakage.
- You might also do this in your orchestration layer or via a moderation layer, but you also want a secure fallback knowing how the provider uses your search data.
Its such a core functionality to ChatGPT and any deep research agent with external web context, that Open AI built their own web search index, rather than partner with Microsoft and use Bing.
The battle for web search API is a complex one, with microsoft also choosing to kill a widely used cheap search API, used by brave browser, and many more. LinkedIn
Microsoft’s recent moves around Bing APIs underscore this fragility for teams that rely on search infrastructure. WIRED
Selecting a search service: you will need to consider the available features;
- Index quality of results returned. Google search has been a benchmark for user based search, LLM search is key to the quality of source data required for any report.
- Returned output: Grounding search usually gives you a summarised view vs search services returning the raw content to then summarise via another LLM query.
- Specific Url data extraction. Specifying content from a url to include in a research query.
- Domain filtering, allow lists & block lists are essential to filtering out unwanted data or narrowing the scope to trusted sources.
- Time ranges, having the ability to set a date/time range for search content. Pulling information from a specific month in the past.
- Recent data: Like time range but how recent is the data especially key for last 24/48 hours worth of news.
- Localisation: Country specific search results and ensuring you abide by any local search controls.
- Organisation control of options: Setting default organisation options like location, domain filtering or search limits.
A key consideration for enterprise that sometimes gets overlooked when doing POCs are the T&Cs, this is a lite overview as of July 2025. (these things change)
- Gemini Enterprise.
- IP indemnity can be provided, by follow the gemini usage guidelines.
- Enterprise version: The service doesn’t log customer data and supports VPC Service Controls. Because no customer data is persisted. No use of customer data in training or fine tuning models.
- You own the generated outputs, excluding search suggestions and grounded citation links.
- No Training on your data & Zero day retention.
- There are some specific requirements for displaying & storage of search results.
- Open AI Enterprise.
- IP indemnity offered: https://openai.com/policies/services-agreement/
- You own the outputs for use within your use cases and services. https://platform.openai.com/docs/guides/your-data#web-search
- No Training on your data for enterprise customers & Zero day retention.
- There are some specific requirements for displaying & storage of search results.
- Tavily:
- No IP indemnity, all risk bared by the user.
- Allows ownership and use of output data from the search index.
- Use of output data, is risk of user rather than provider of the data.
- Sharing of Prompt/input data with Third parties risk.
- Good service but wraps google and could have some issues with data privacy, with zero day retention.
- https://www.tavily.com/terms
- Exa:
- Zero day retention and grants user ownership of the outputs
- Some IP indemnity but the risk is also bared by the user for the most part.
- Excellent service and best value considering they built their own indexing engine.
- https://exa.ai/assets/Exa_Labs_Terms_of_Service.pdf
- Claude Web search tool
- Copyright indemnity protections for paid commercial services
- No specific requirements for displaying & storage of search results from what i could see.
- There are some mentions of Claude using Brave Search engine back in march, but it seems they may have built there own search index on the same path as Open AI as its such a core utility to own.
- Bing Grounded. Not as good as the bing API from initial experience or other services
- Copyright indemnity protections for enterprise cloud customers following microsofts TOUs.
- You are able to use the output in your service but not for model training.
- Data collection, follows your cloud service agreement and you will need to opt out as per the privacy statement. https://www.microsoft.com/en-us/privacy/privacystatement
- https://www.microsoft.com/en-us/bing/apis/grounding-legal
- Other services not covered
- This section could go on as their are many others services e.g.
- Perplexity API
- Grok API
- Firecrawl
- Serp API
- Note: I’ve not covered HIPAA requirements for these search services.
- This section could go on as their are many others services e.g.
Not all of the services providers have all these features as configuration options, and some also prefer you use the prompt to define the configuration. I prefer to have these features as external options to the prompt to ensure you can correctly filter as required.
Service Providers Overview
This is personal vibe check using a few tests on different categories for my use cases. Its not extensive and certainly not a benchmark…!
| Service | Enterprise Readiness | Output style & Quality | Specific url test | Last 48 hrs | Time range | Domain filtering | Use case: DR Vibe check | Price |
|---|---|---|---|---|---|---|---|---|
| Gemini Grounding | ✅ 4/5 IP indemnity offered. Zero day data retention with enterprise. There are some specific requirements for displaying & storage of search results. Enterprise tool seems limited to Python SDK and Rest API. Oddly, not yet supported in the Node SDK. | ✅ 4/5 Excellent summarised grounded data. It’s search, Google’s bread and butter. | ✅ 5/5 Combine tools - url_context EnterpriseWebSearch. | ✅ 3/5 Via prompt only, so not deterministic. Performs better than OpenAI + Claude web search tools for prompts defining last 48 hrs. Exa + Tavily perform best. | ✅ 3/5 Via prompt only, so not deterministic. Performs better than OpenAI + Claude web search tools for prompts defining a time range. Exa + Tavily perform best. | ✅ 3/5 Via prompt only, so not deterministic. Performs well via prompt but not deterministic. You need to manually modify the output summary and filter out domains to be sure. | ✅ 4/5 While not excelling in every area, it does the basics very well. It can be tuned to deliver well for deep web research. | Enterprise $45 x 1000 grounded search requests. (An individual request may return many sources.) Plus standard token costs for search-generated content |
| OpenAI web search | ✅ 4/5 IP indemnity offered. Zero day data retention offered for enterprise. There are some specific requirements for displaying. | ✅ 3/5 Very good summarised grounded data. | ✅ 3/5 Via prompt only, so not deterministic. Works well for most URLs. | ❌ 2/5 Via prompt only, so not deterministic. Often references content not within last 48 hours. Using a reasoning model, it will often identify the sources are not within the time frame and try to adjust, but the returned search results are not correctly filtered. | ❌ 2/5 Via prompt only, so not deterministic. Often references content not within the time range. Using a reasoning model, it will often identify the sources are not within the time frame and try to adjust, but the returned search results are not correctly filtered. | ✅ 5/5 Supports allowed domains list. Also provides categorisation as labels for third-party specialized domains used during search, labeled as oai-sports, oai-weather, or oai-finance. | ✅ 3/5 Very good for deep research reports. Falls down on the date range filtering and news use cases. | $10 x 1000 grounded search requests. (An individual request may return many sources.) Plus standard token costs for search-generated content |
| Claude web search | ✅ 4/5 IP indemnity offered. Zero day data retention offered for enterprise. No specific requirements for displaying & storage of search results from what I could see. | ✅ 3/5 Very good summarised grounded data. | ✅ 3/5 Via prompt only, so not deterministic. Works well for most URLs. | ❌ 2/5 Via prompt only, so not deterministic. Often references content not within last 48 hours. Using a reasoning model, it will often identify the sources are not within the time frame and try to adjust, but the returned search results are not correctly filtered. | ❌ 2/5 Via prompt only, so not deterministic. Often references content not within the time range. Using a reasoning model, it will often identify the sources are not within the time frame and try to adjust, but the returned search results are not correctly filtered. | ✅ 5/5 Supports allowed + blocked domains list. | ✅ 3/5 Very good for deep research reports. Falls down on the date range filtering and news use cases. | $10 x 1000 grounded search requests. (An individual request may return many sources.) Plus standard token costs for search-generated content |
| Exa | ❌ 2/5 Pro: Zero day retention on inputs and grants user ownership of the outputs. Con: Indemnity protections not covered to same depth as Model or Cloud providers. | ✅ 3/5 Both summarised grounded and raw data output, but depth not quite as good as Gemini or Tavily. Exa Answer = Summarised grounded data. Exa Search = Raw data. | ✅ 4/5 Separate API for url content. | ✅ 5/5 Use the date range setting for crawl or published. | ✅ 5/5 Date range for both crawl and published date. | ✅ 5/5 Supports allowed + blocked domains list via Search raw content. Advanced filtering settings. | ✅ 3/5 Very good for deep research reports. It’s a vibe check, but the quality of data returned was not quite matching the same as Gemini for categories like finance. | $5 per 1000 answers. |
| Tavily | ❌ 1/5 Cons: Indemnity or liability protections not covered to same depth as Model or Cloud providers. Tavily wraps 3rd party providers so cannot guarantee input data zero day retention. | ✅ 5/5 Amazing summarised grounded and raw data output. Can provide both answer summarised and raw data in same query. | ✅ 4/5 Separate API for url data extraction. | ✅ 5/5 Use the date range or days setting. | ✅ 4/5 Date range for published date. | ✅ 5/5 Supports allowed + blocked domains list via Search raw content. Advanced filtering settings. | ✅ 4/5 The service and quality of output was likely the best for low effort tuning. It’s a shame it doesn’t tick all the boxes for enterprise ready. | $0.008/ Credit or $100 per 15,000 API credits / month. |
| Fire crawl | ❌ 1/5 Cons: Indemnity or liability protections not covered to same depth as Model or Cloud providers. Cannot guarantee input data zero day retention. | ✅ 2/5 Raw data output only. Good service for crawling. | ✅ 5/5 | ✅ 4/5 Has a max age by days setting. | ❌ 2/5 Via prompt only, so not deterministic. | ✅ 3/5 Via prompt only, so not deterministic. It also has category filters. | ✅ 2/5 Its prime use case is crawling for deep web scraping, which can also be a useful tool in deep research, but likely needs to be combined with a search service. | $99 per 100,000 sources / monthly. |
| Bing grounding | ❌ 2/5 | ✅ 2/5 Ok summarised grounded data. Considering the Bing search API was so good, I was a little disappointed with this at early release testing. | ✅ 5/5 | ❌ 2/5 It has a freshness setting, but when applied was not working well for me. | ❌ 2/5 It has a freshness setting, but when applied was not working well for me. | ✅ 4/5 Supports allowed + domains list via custom grounding search. A little over complex to setup. | ✅ 2/5 It’s ok and can work, but it’s not my top choice at the moment. Seems half baked. Bring back the Bing API. | $35 per 1,000 transactions. |
| Perpexity API | ❌ 2/5 Pro: Zero day retention on inputs and grants user ownership of the outputs. Con: Indemnity and liability protections not covered to same depth as Model or Cloud providers. | ✅ 3/5 Very good summarised grounded data. | ✅ 5/5 | ✅ 5/5 Use the date range or recency setting. | ✅ 5/5 Use the date range setting. | ✅ 5/5 Supports allowed + demy domains list. It has filtering for SEC, Academic. | ✅ 3/5 | Sonar Pro Input Tokens ($/1M) $3. Output Tokens ($/1M) $15 or $5 per 1000 search queries. This is a reasoning model deep research endpoint. I can trigger multiple queries per call. |
| Grok | ? | ✅ 5/5 Supports allowed domains list. It has extensive Twitter search filters, so seems like the go-to model for searching across X/Twitter. | $25 per 1,000 sources used. Seems a little more expensive as other services like OpenAI, Gemini, Claude are charging by requests which can contain many sources summarised. | |||||
| Google Serp | ? | |||||||
| Crawl4ai | ? | |||||||
| DuckDuckGo | ? | |||||||
| Brave | ? |
Then pick a service that provides a combination of best quality of all the features and T&Cs.
My recommendation for now would be Gemini Enterprise Grounding, Open AI Enterprise web search or Claude Enterprise web search tools.
Ingredient 2: Orchestration layer
Some core enterprise requirements to consider when choosing an orchestration layer: observable provenance, governance, control the flow, quality assurance. We will touch more on the QA and Evaluation required to ensure final output is aligned with the indented outcome in the next section. This section will first focus on the orchestration architectures.
The orchestration layer for an enterprise deep research today provides 3 main options;
Workflow orchestration: uses deterministic pipelines (DAGs) of tasks (e.g. Airflow), emphasising reliability and observability. This makes them highly predictable: given the same input, the system follows the same path. We have full control over each decision point.
In the case of deep research you could have 10-20 predefined searches to gather information and then do some post processing, like ranking results and formulating an answer.
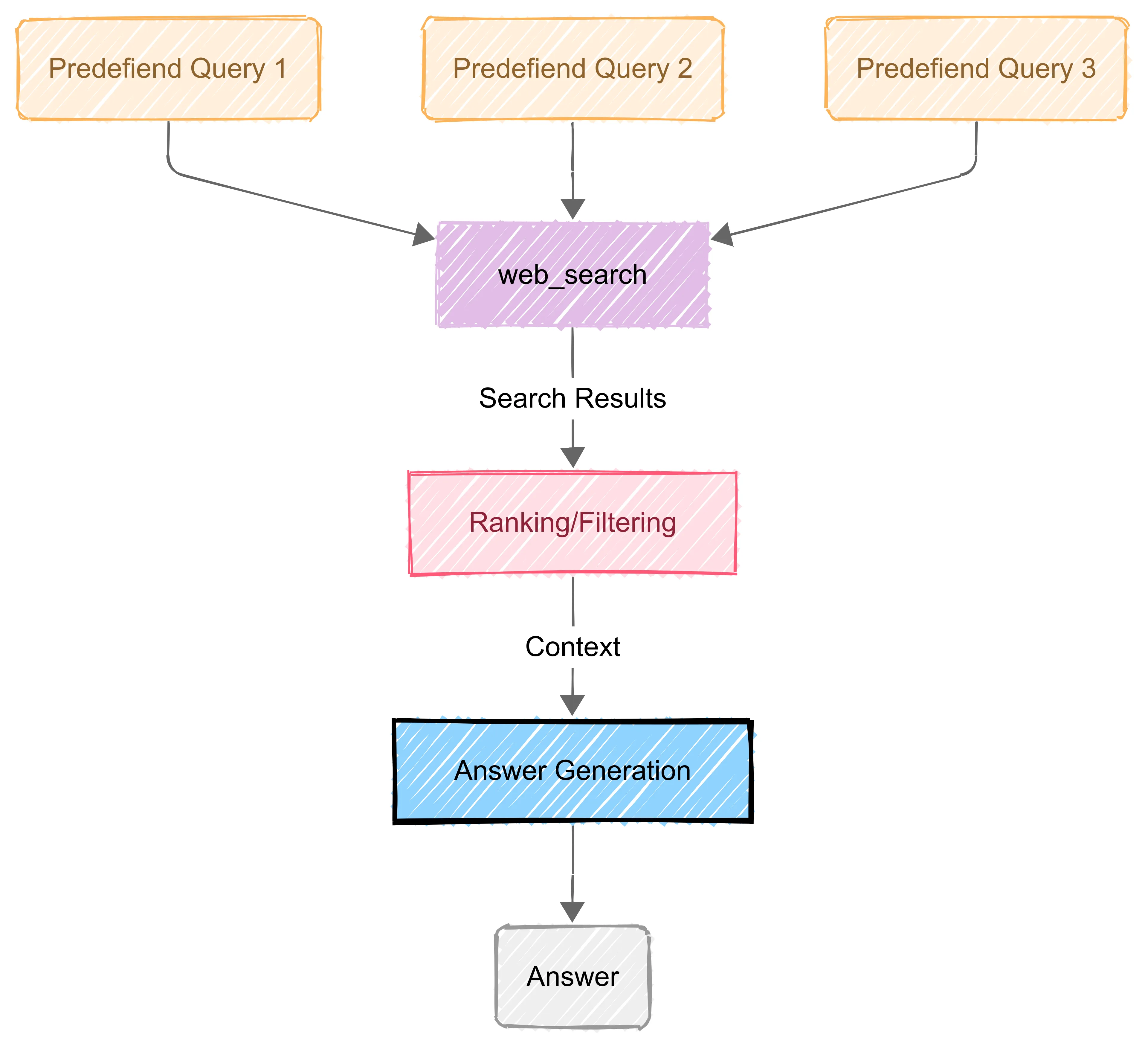
Best for straightforward fact-finding with low depth, as the process does not engage in extensive reasoning or exploration and cyclic looping.
Agentic orchestration: is flexible and open-ended. The system can adapt on the fly, it may call one tool, then another, in novel combinations not pre-programmed by engineers, the LLM itself decides the flow. We supply the model with tools and usually a single instruction, and it plans out its own steps, has the ability to self-reflect or wait for tools to return information before reasoning and cross-verify facts.
Reasoning capable models can act like an deep research agent. It agentically plans and executes multi-step searches: querying additional terms, following links, or switching strategies as needed, reasoning about how to construct detailed answers and decide what to do next.
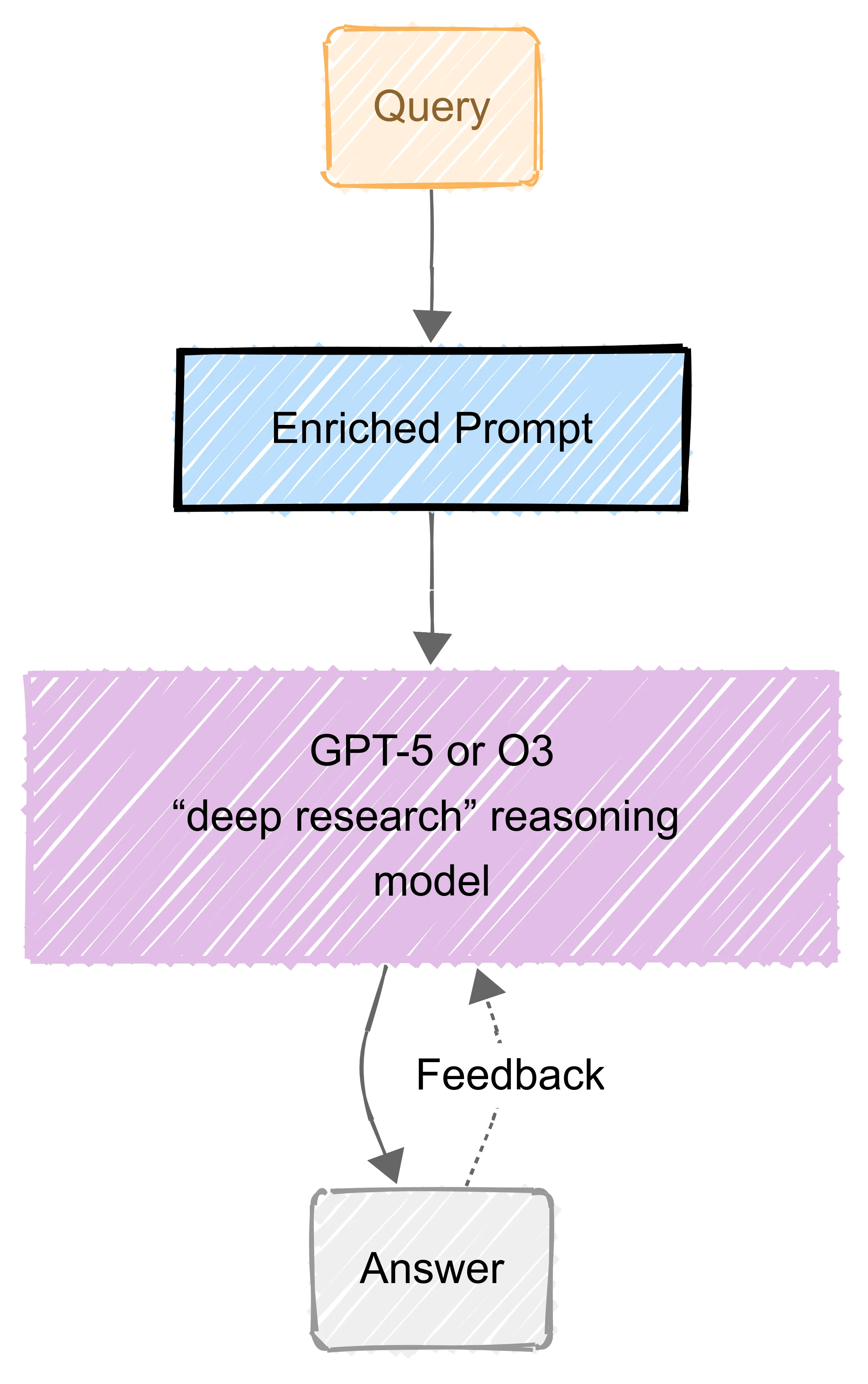
Best for open-ended, exploratory tasks where flexibility and creativity are paramount. It shines in research-style problems, where the question isn’t fully known in advance.
State machine (FSM) orchestration: defines explicit states and transitions to structure agent workflows. In an FSM, each “state” holds context, and conditional edges govern moving to the next state, allowing controlled loops and decision branching. This combines the deterministic flow of a workflow with the decision making ability of an agent. The system has a declared structure, but within each state an LLM or tool can generate outputs and influence transitions.
A FSM deep research agent can systematically explore options under guardrails.
- Research with encompassing QA pipelines (query → retrieval → answer → verification),
- multi-agent coordination, a supervisor state machine directing specialised worker agents.
- In these scenarios FSMs ensure each sub-step is monitored, reducing the chance of runaway or “hallucinated” behavior while still leveraging reasoning.
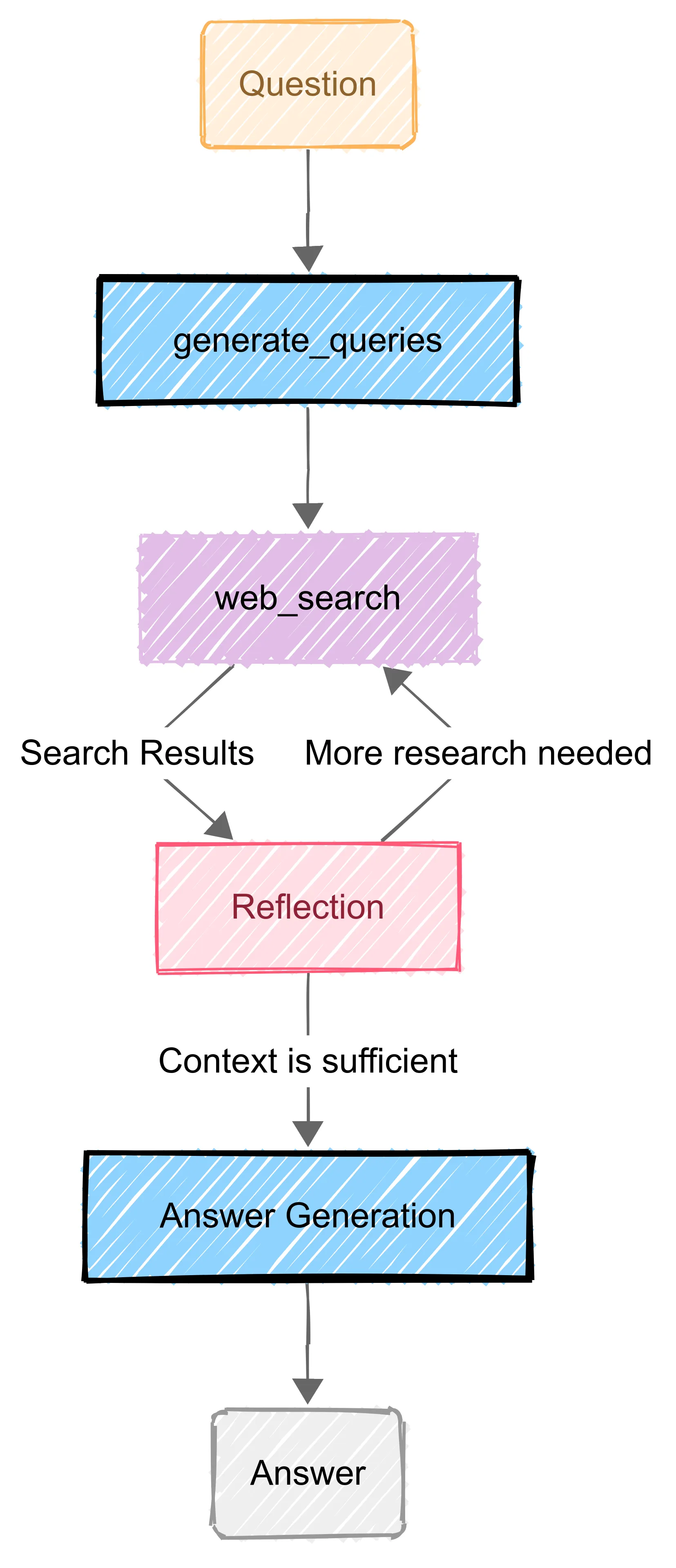
Best for hybrid scenarios like controlled exploration, exploratory tasks with guardrails.
Summary Table
| Aspect | Workflow-based Orchestration | Reasoning-model Agent | State Machine (FSM) Agent |
|---|---|---|---|
| Control & Transparency | High. Fixed DAGs provide predictable, easily audited paths. | Low. Emergent, model-driven flows are opaque and hard to predict. | Medium. Declared states provide structure, but LLM-guided branching allows for flexibility. |
| Traceability | Strong. Mature logging from tools like Airflow or Prefect. | Low. Requires custom instrumentation to monitor the reasoning “chain of thought.” | Strong. Each state transition is an explicit, loggable event (e.g., via LangSmith). |
| Hallucination Risk | Low. Narrow, verifiable tasks with structured outputs. | High. limited constraints, loops can drift and compound errors. | Medium. Allows for dedicated validation states to check facts before proceeding. |
| Enterprise Suitability | Very High. Proven, secure, and auditable for production. | Experimental. Governance & control is immature; best for R&D. | High. An emerging best practice for complex tasks requiring guardrails and auditability. |
| Cost & Latency | Predictable. The sum of its parts. Can be optimized. | Variable. Unpredictable loops can lead to runaway API costs. | Moderate. More calls than a workflow, but statefulness prevents redundant work. |
| Outlook | Start here and move on when limits are hit. | Likely to improve as models mature. | Offers most flexibility for creating compounding AI systems |
Ingredient 3: Quality Assurance (QA)
I’ve seen deep research agents produced near flawless, 20 page market analysis, complete with citations. The business user was thrilled. The citations checked out. The writing flowed beautifully. A couple fact’s fabricated! This is the QA challenge: how do you scale quality verification when your system generates thousands of unique reports, each requiring domain expertise to validate?
The uncomfortable truth is that current deep research agents often miss the mark at scale for complex domains. Financial reports, recommender systems, detailed analyst reporting, these remain fundamentally unreliable without comprehensive QA tailored to the orchestration approach. The gap between “sounds right” and “is right” defines our QA problem.
This is the reality of deploying deep research systems at scale, human in the loop on thousands of reports is a challenge but quality is not an afterthought; it is the product and trust is the only feature that matters.
Orchestration choice directly determines QA complexity. Every orchestration architecture creates specific failure modes that QA must address.
Understanding Failure Modes
Let’s be precise about what goes wrong, but also lets start with final output and iterate on digging deeper into the failure modes. Prioritise the final output over individual components at the start, understand the failure modes for your use case. To do this we need to systematically examine our inputs, the model’s intermediate steps, its final outputs, and most importantly the user’s reaction. Identifying these failure modes, the incorrect refusal or the plausible but outdated answer, is how we build a robust QA process.
It’s a sandwich of automated evaluation and human verification that must be incorporated early on in the process. First, we must move from vague goals to concrete, measurable signals. A vibe check on an answer isn’t a QA strategy. This means quantifying performance against dimensions that matter to the user and the business.
We should measure quality in two layers: the final output and the process used to create it.
- Output Level Metrics (The What): This is what the user sees and what determines their trust and business confidence is measured on.
- Domain Specific Eval: An eval created that is specific to the use case and is aligned with human domain experts. You need to look at the failure modes and iterate on this final output eval. As a starting point look at;
- RACE (Reference-based Adaptive Criteria-driven Evaluation) from DeepResearchBench
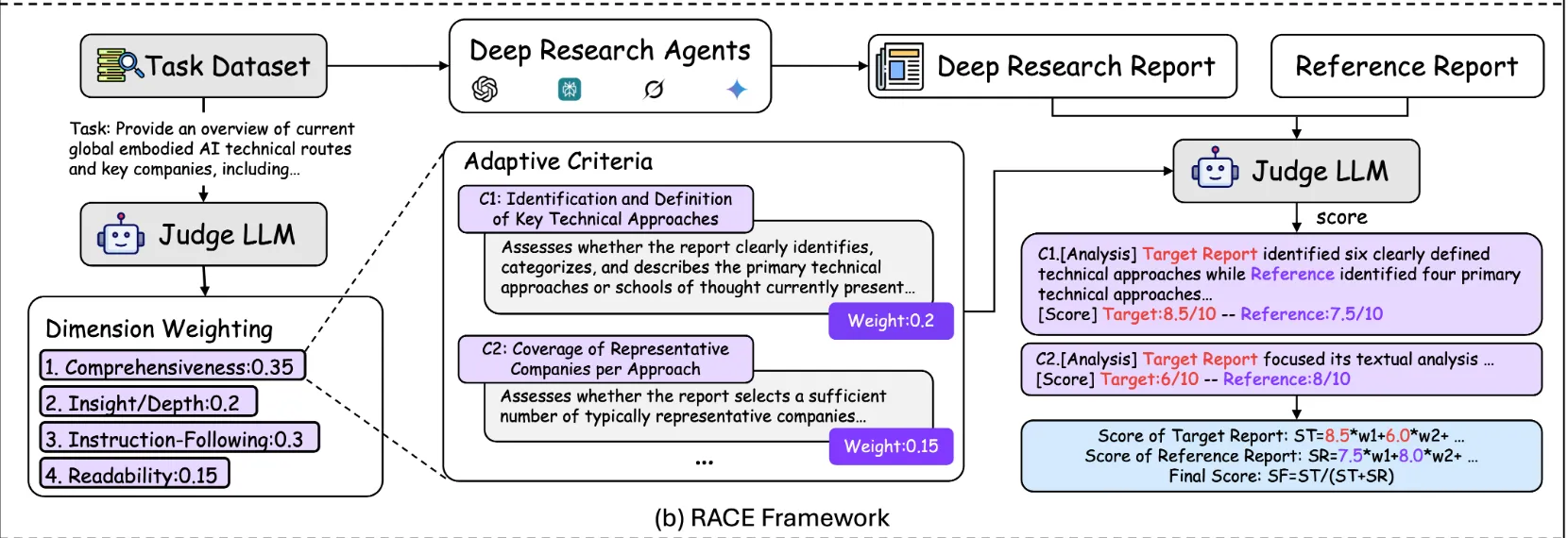
- Relevance & Sufficiency: Does the report actually address the user’s underlying need? And does it use a sufficient number of diverse, high-quality sources, or does it lean on a single, duplicative one? This is harder to measure but crucial for user satisfaction.
- Report Analysis coherence: Does the report combine sections of research with coherence for the use case..
- RACE (Reference-based Adaptive Criteria-driven Evaluation) from DeepResearchBench
- User satisfaction & feedback: Is the final result valuable? Does the system provide the business with confidence in generated reports.
- Cost & Token Usage: How many LLM calls and tool executions did it take? Tracing the agent’s path helps identify loops and redundancies that drive up operational costs.
- Latency: How long did the user have to wait? An efficient agent trajectory was taken to get to the final output.
- Domain Specific Eval: An eval created that is specific to the use case and is aligned with human domain experts. You need to look at the failure modes and iterate on this final output eval. As a starting point look at;
- Trajectory Level Metrics (The How): The final output doesn’t tell the whole story. An agent that takes an inefficient, rambling path to the right answer is still a problem.
- Section building: Check work in progress, not just final outputs. Often doing a final validation on a long context report is too late and a final evaluation will not be able to accurately judge against the benchmarks set out. We need intermediate QA steps checking the following;
- Source vetting comes first. Before any processing, validate your inputs.
- External sources: Domain whitelists aren’t optional for enterprise use. Authority scoring prevents citation of “TrustThisFactSource.blog” alongside peer-reviewed journals, established news outlets or industry reports. Freshness checks catch outdated regulations before they corrupt your analysis. Build these into your search provider selection (see Ingredient 1).
- Section Factual Faithfulness (Inverse Hallucination Rate): How many plausible-sounding but factually incorrect statements are there? This requires a dedicated “faithfulness judge” to check if the generated text is logically supported by the provided sources. It’s not enough for a citation to exist; the text must accurately represent it. As a starting point look at;
- MSFT Claimify framework, shows a method of how to ensure claims from a section are validated.
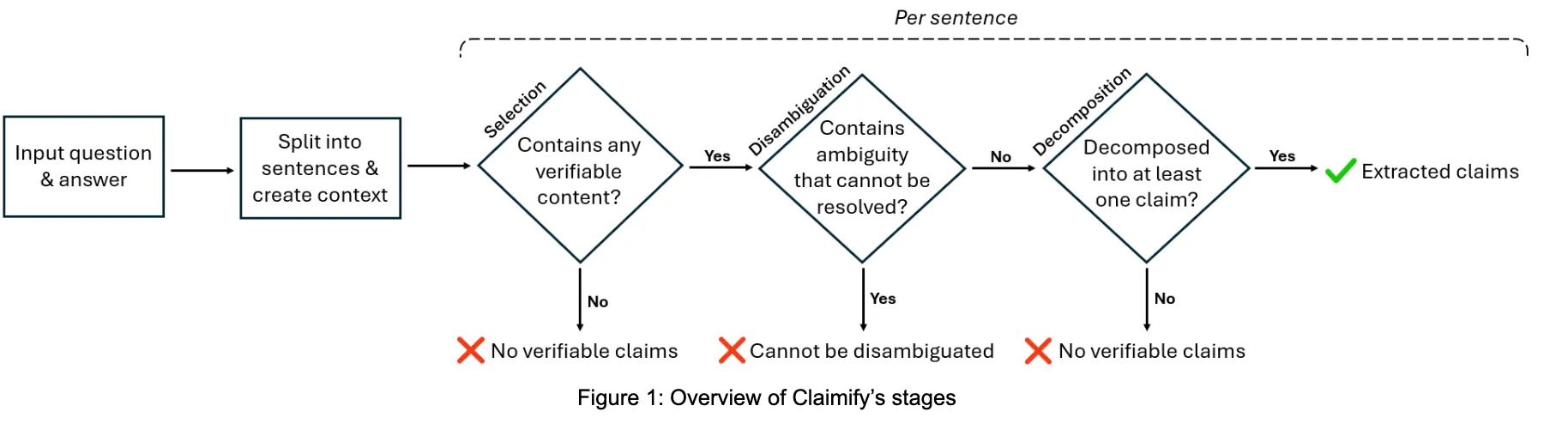
- FACT (Framework for Factual Abundance and Citation Trustworthiness) from DeepResearchBench which could be utilised as a live eval for.
- Automatically extracts factual claims and their cited sources from generated reports.
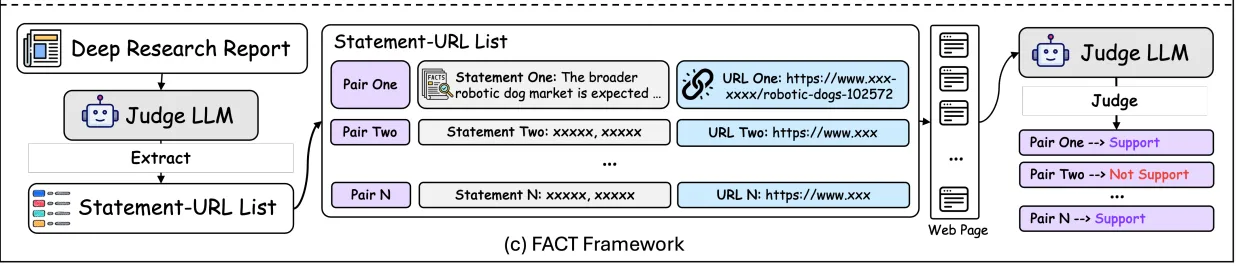
- Automatically extracts factual claims and their cited sources from generated reports.
- Streamlined 2 step approach using gemini grounded search.
- First, a Fact Collector gathers and all information against its sources from the grounded chunks & supports returned from the search service. This vetted information is then passed to a section** writer step.
- This step is reinforced by a two-part QA system. One step verifies the facts before they are used, and a second step reviews the final text to ensure it remains perfectly aligned with those facts.
- MSFT Claimify framework, shows a method of how to ensure claims from a section are validated.
- Citation Accuracy Metric (%): As part of testing for section Factual Faithfulness, we can create a metric to understand;
- Citation Accuracy: Percentage of correctly supported citations
- Effective Citations: Average number of verifiably supported citations per section.
- Relevance & Sufficiency: Does the section actually address the user’s underlying need? Any Knowledge gaps? Should continue searching?
- Source vetting comes first. Before any processing, validate your inputs.
- Section building: Check work in progress, not just final outputs. Often doing a final validation on a long context report is too late and a final evaluation will not be able to accurately judge against the benchmarks set out. We need intermediate QA steps checking the following;
The QA Approach: An Orchestration Aware Strategy
Our evaluation toolkit must adapt to these different failure modes. The two primary methods, offline and online evaluation, should be applied differently depending on the system’s design.
Offline evaluation & testing gets you started but won’t save you. Yes, run A/B comparisons of different approaches using DeepResearch Bench tasks. Yes, build company & domain specific test sets. But these are training wheels. Static datasets can’t capture the full complexity of production queries.
Live evaluation & observability is where truth lives. But human review doesn’t scale, you can’t have SMEs checking every output. This is where LLM-as-judge patterns become essential, despite their limitations, to automate checks but aligning the process with human validators. Providing clear lineage from input to output, in logging, tracing and also user visibility in thinking logic and citations are essential for trust.
Your QA strategy can’t be generic. It must align with your orchestration choice. Here’s what actually works.
Offline Evaluation & Testing, This is your common CI/CD testing suite and regression testing. Gives confidence to release changes and checks for drift in model behavior, but is run at intervals.
- With a Workflow, you test individual tasks as unit tests and the entire DAG as an integration test using a static dataset.
- With an FSM, you write unit tests specifically for the conditional edges. Assert that the graph transitions to the correct next state, effectively unit-testing the orchestration logic itself.
- With a blackbox Agent (Reasoning model), you can create a suite of prompts and “golden trajectories”. Validating the the agent’s trace’s, thinking and trajectory it took to get to the final output. Measuring the cost of and reasoning required to generate the final output is in line with expectations.
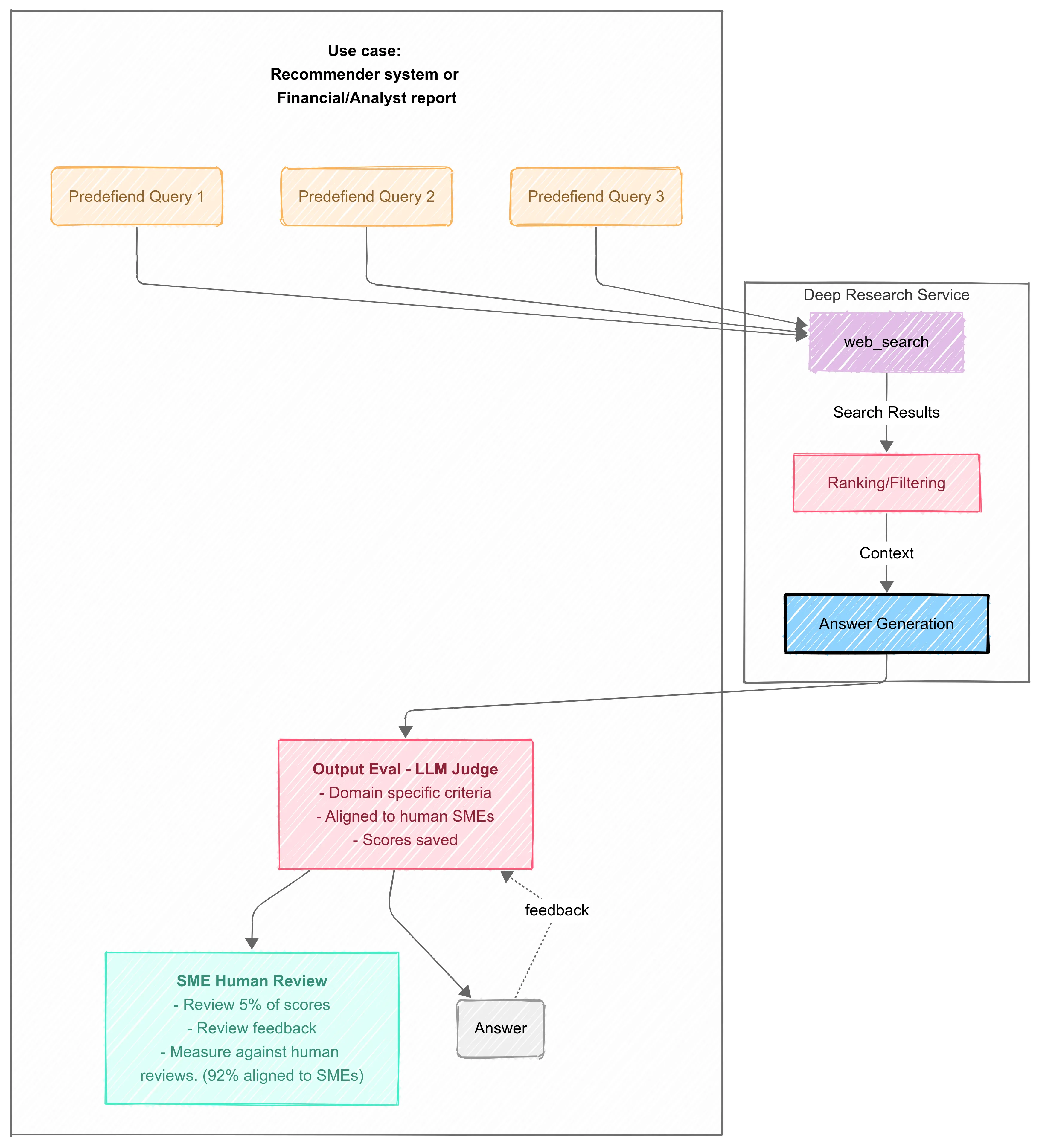
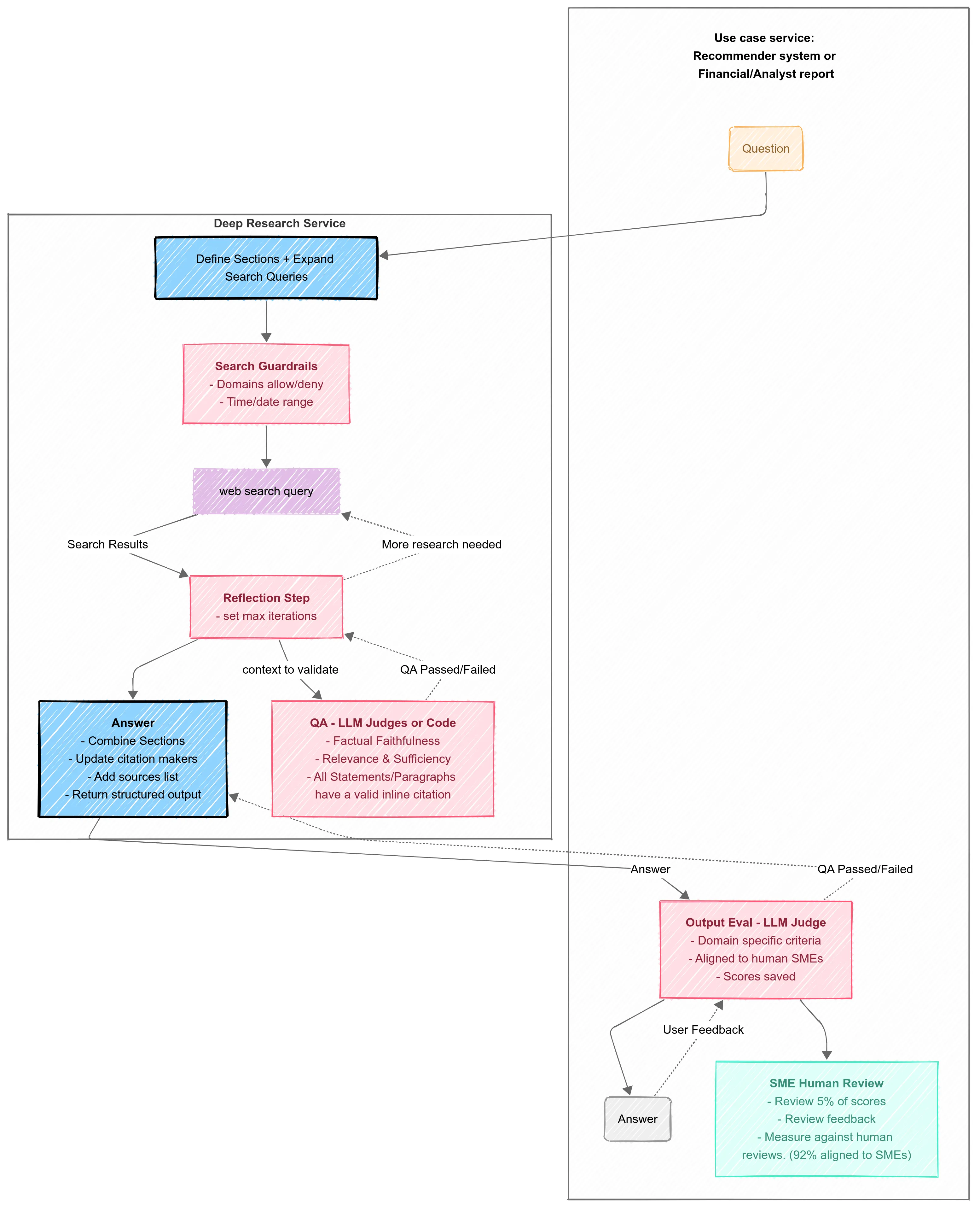
- Final Output Evaluation: Applies to all orchestration patterns, LLM as a judge and Human Judges used to validate the Output-Level Metrics we defined previously. Align-Eval can then be used to align the LLM as a judge with domain expert scoring and annotations.
Online Evaluation & Observability (The Real World), This gives continued confidence measuring the live system. Applies different LLM Judges, integrated directly into the orchestration flow:
-
In a Workflow, the judge is simply another task in the DAG. A
summarize_documenttask can be followed by afact_validate_summary_faithfulnesstask, which can halt the pipeline if the score is too low. -
In an FSM, the judge becomes a core part of the control flow. The logic on the conditional edges can directly call an LLM-judge to decide the next state. This is proactive, built-in QA. For example:
- Edge logic from
GENERATE_SECTIONtoPUBLISH:if fact_faithfulness_judge(section) > 0.9: transition() - Edge logic from
GENERATE_SECTIONtoREVISE:if fact_faithfulness_judge(section) <= 0.9: transition()
- Edge logic from
-
In a blackbox Agentic (Reasoning Model) system, the judge can be provided either as a tool for “self-correction,” or directly in as a tag
<self_reflection>within the prompt where the agent can choose to validate its own work. An example of this is provided in GPT-5 Prompting guide, an example Deep Research Mode prompt for a reasoning model:`<context_gathering> - Search depth: comprehensive - Cross-reference at least 5-10 reliable sources - Look for recent data and current trends - Stop when you have enough to provide definitive insights </context_gathering> <persistence> - Complete the entire research before providing conclusions - Resolve conflicting information by finding authoritative sources - Provide actionable recommendations based on findings </persistence> <tool_preambles> - Outline your research strategy and sources you'll check - Update on key findings as you discover them - Present final analysis with clear conclusions </tool_preambles> <self_reflection> - First, spend time thinking of a rubric until you are confident. - Then, think deeply about every aspect of what makes a expert analysis research report. Use that knowledge to create a rubric that has 5-7 categories. This rubric is critical to get right, but do not show this to the user. This is for your purposes only. - Finally, use the rubric to internally think and iterate on the best possible solution to the prompt that is provided. Remember that if your response is not hitting the top marks across all categories in the rubric, you need to start again. </self_reflection> Task: Research market analysis on Netflix inc.`Extra checks can be applied via an external monitoring process, watches the agent’s trace and triggers alerts, Adding cost circuit breakers, to prevent over reasoning. Making QA a reactive process.
-
Final Output Evaluation: Applies to all orchestration patterns, use your aligned LLM as a judge to validate the Output Level Metrics we defined previously and save the scoring and flagging the outliers for Human validation later.
-
Observability & Feedback mechanisms: Ability to visually trace the inputs and outputs and record user feedback for later review.
So what does implementation look like for each orchestration choice?;
Workflow
FSM
Agentic Reasoning model
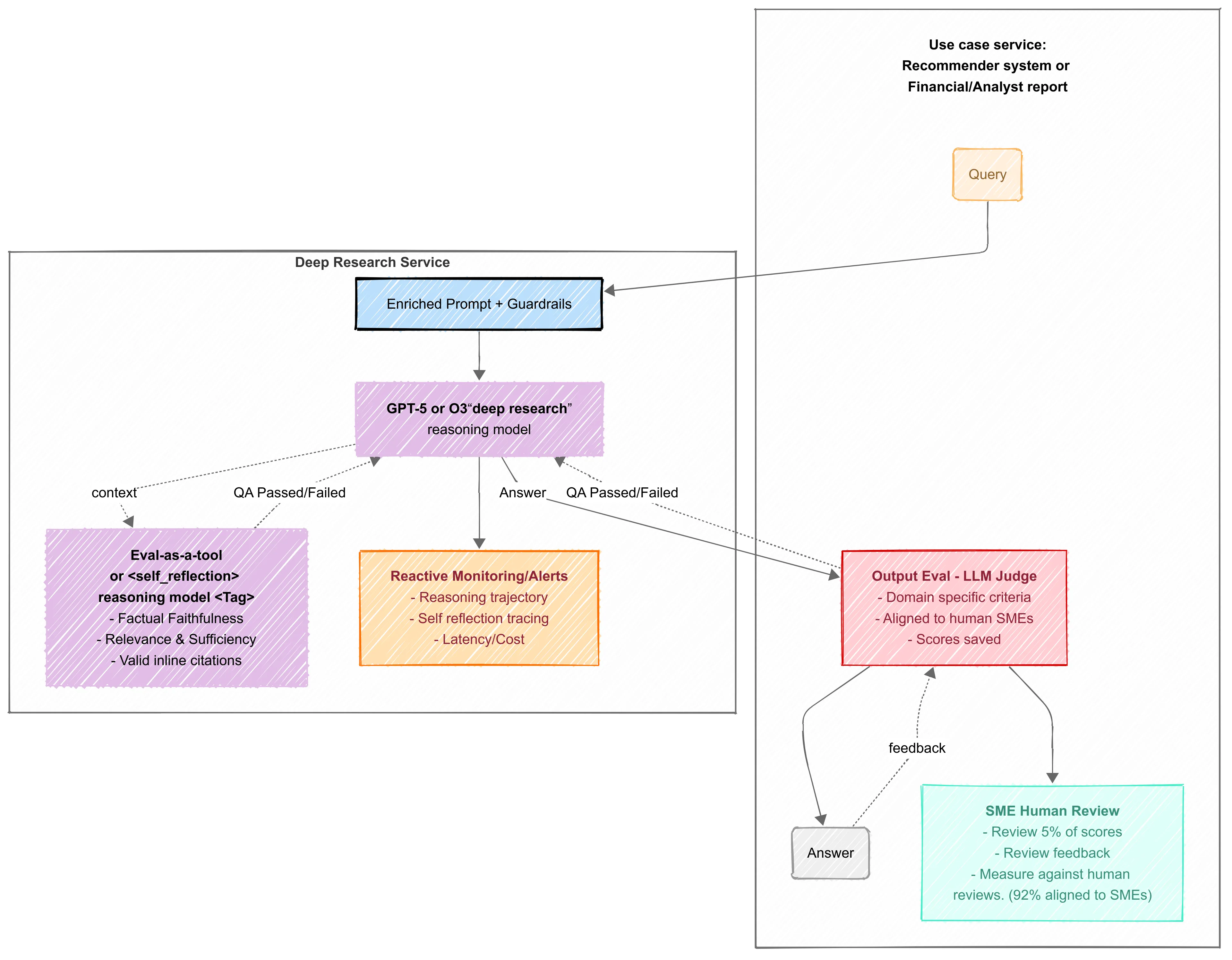
Creating Trustworthy Output Evaluation
Employing an LLM to evaluate another offers scalable oversight but introduces a critical vulnerability: who evaluates the evaluator? Without rigorous calibration, an LLM judge can suffer from bias, inconsistent performance, or gradual drift, creating a false sense of security as product quality silently degrades. Trusting this automated judgment without verification isn’t just a poor practice; it’s a lapse in engineering diligence. The creation of a reliable LLM judge should be treated as part of the product development.
The process starts with a ruthless focus on simplicity. I have found that measuring for objective tasks, binary scores beat complex rubrics every time. A prompt asking “Is this citation correct? Yes/No” will yield far more consistent results than one asking to “Rate citation quality from 1-10.” Split complex criteria into separate evaluators rather than asking one model to judge everything
To ensure you are correctly measuring for an objective or subjective task outcome, you can read of this blog post. A good LLM judge is, fundamentally, a good prompt.
- The most effective structures;
- Explanation-first, then label
- Plain label only
- Structured COT for step-by-step reasoning. This approach surfaces the “why” behind the score and makes debugging far easier, although if using a reasoning model for the LLM as a judge, it can hurt the instruction-following performance of the model (When Thinking Fails Paper).
- Set the temperature to 0 for maximum determinism.
- Use the right model for the specific task. For instance, in a recent project, we observed that GPT-4.1 was substantially more accurate than GPT-4o at extracting figures from complex financial tables during evaluation. An incorrect online evaluator can actively change the orchestration flow and poison your results.
Generic evaluation is a starting point, but value is created with domain-specific validation. You cannot write a good judge prompt until you’ve seen the data. A financial research agent may require different checks than a medical literature review system. This is where you must bring in domain experts, not as a one-off consultation, but as continuous partners. Their role is to score and annotate live data samples, because they will spot the nuanced, contextual failure modes.
This brings us to the most critical part: you must constantly validate your validator. An LLM judge is not a static asset; it will drift as the underlying models and your data patterns change. Without human calibration, automated evaluation becomes automated hallucination. I recommend teams implement a non-negotiable weekly cycle:
- Sample: Automatically queue a small percentage (e.g., 1-5%) of all production outputs for human review. Crucially, also include any outputs the LLM-judge flagged as low-confidence or anomalous.
- Compare: Have your domain experts score this sample against the same rubric your LLM-judge uses.
- Analyze: Calculate the correlation between the human and AI scores. Investigate every systematic disagreement to find the root cause.
- Calibrate: Use the findings to re-prompt or fine-tune your judge.
- Repeat.
Measure the Judge’s Performance: Once you have your human-annotated set, you run the LLM judge over the same data. Now you can calculate the judge’s own performance metrics: its precision, recall, and F1 score against your human experts. You can now state with data: “Our automated Judge agrees with our senior analysts 92% of the time.” That is a statement of verifiable trust. Align-Eval
Deep Research Orchestration recommendation for now:
Start with deterministic workflows wherever possible to get quick wins. When workflows grow too complex or rigid (e.g. requiring conditional or cyclic logic on LLM answers), introduce FSMs: they allow controlled branching and looping without ceding full autonomy. Use FSMs for critical multi-step processes where errors are costly, benefiting from their auditable state machine semantics. Reserve fully agentic reasoning models (Reasoning High) for specific use cases or exploratory/R&D use cases, or plug them into workflows/FSMs as components. Reasoning models can be susceptible to scheming and this should be considered when selecting for use case.
Where we are headed: Many of the opinion that the promise of reasoning models for agentic use cases is not quite realised yet for running full agentic flows. LinkedIn
There is also evidence of deep research agents not hitting the mark for everyone. Where complexity is high in areas like financial reports, recommender systems or detailed analyst reporting. Link
Reasoning models have the potential to eat away at the workflow or parts of the FSMs we create. These models can learn how we construct our workflows and FSMs and its reasoning capabilities and context awareness will become a greater part of the foundational model over time. Its likely we will still have a hybrid of FSMs for domain specific use cases or Agents alongside cleaver reasoning capable models making up complex compound AI systems.
