So are Deep Research Agents Enterprise ready?

The rapidly reshaping landscape of Deep Research agents this year has been incredible to the point where they look enterprise ready. I recently sent a simple brief to a Deep Research agent:
“Give me a 4-page company profile and current business overview on Apple, with high quality in-line citations.”
Ten minutes later I had a structured outline, with 30 sources, and a detailed company analysis. It feels a bit like magic until I checked some of the sources and fact checked some of the financial figures. The good news: modern agents can assemble and collate data fast. The uncomfortable news: they still have opaque decision-making, and their notion of “high quality” varies by provider and use case.
Enhancing self learning and speeding up your own research, it’s arguably the biggest headline grabbing use case for generative AI agents to date and something I use a lot. In an enterprise setting, the ask is to utilise deep research across many domains, at the same time giving business confidence at scale, still currently remains a challenge applying with a high level of accuracy and confidence.
We have however got to where we are today fairly rapidly in 2025, Google shipped “Deep Research” to Gemini Advanced on Dec 2024 (Gemini 2.0 / Deep Research rollout). OpenAI followed with its own “Deep Research” capability in ChatGPT on Feb 2025 and published a Deep Research API cookbook in June 2025. Perplexity, xAI, and others launched competing products in February 2025; Google later exposed a Deep Research flow through Agent Space (May 2025). Those releases compressed what used to be hours of desktop research into minutes for many tasks.
That speed of change is also becoming somewhat measurable. The DeepResearch Bench and associated leaderboard evaluated agents on 100 PhD-level tasks and released their methodology and results in mid-2025, creating an empirical baseline for “how good” a deep research agent is across retrieval, synthesis, and citation accuracy. Benchmarks like this matter because they turn vendor blurbs into testable claims. arXiv | Hugging Face
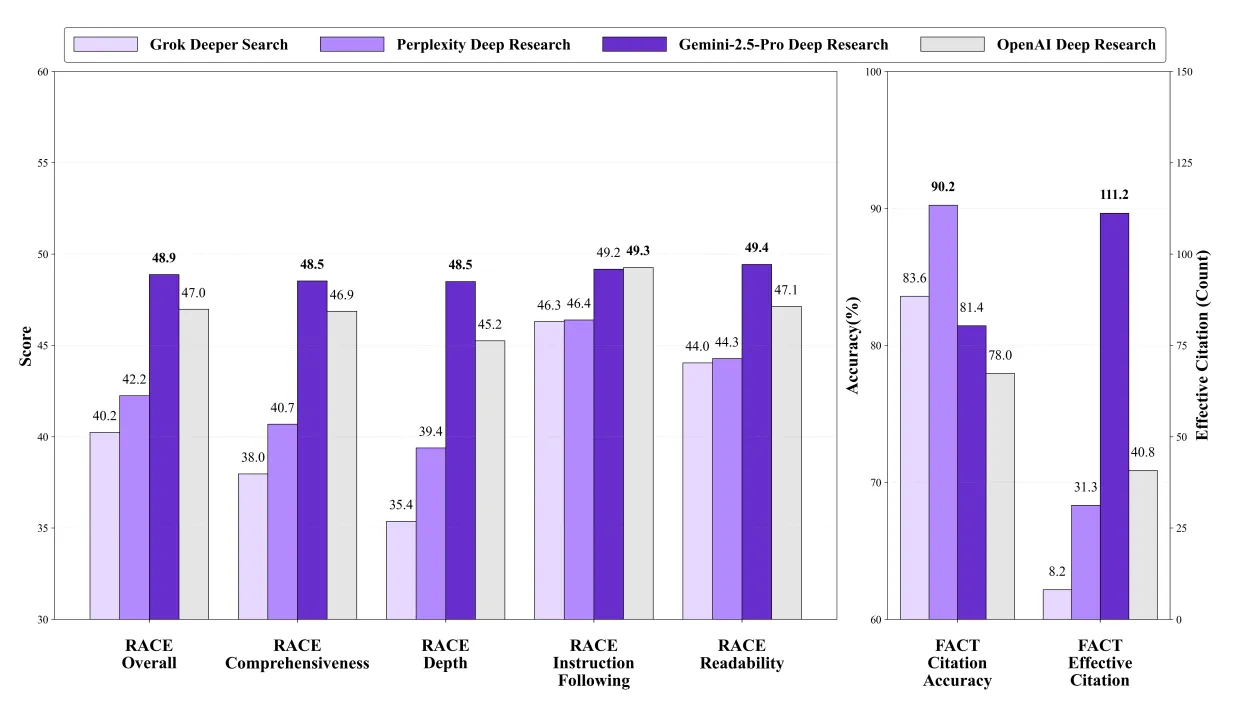
Benchmark measurements has limits though, and I’m skeptical about what these benchmarks actually mean in product terms. Benchmarks typically test closed, well-defined tasks. They reward agents that optimise for the benchmark’s narrow rubric. That’s useful for comparison, but it biases development toward the test’s proxies: citation density, reference recall, and surface plausibility of a static benchmark. The real user problems are messier & always evolving: conflicting or bad sources, evolving facts, proprietary data, and actionability. Benchmarks are directionally informative; don’t mistake them for full validation. The evals used RACE (Reference-based Adaptive Criteria-driven Evaluation) & FACT (Framework for Factual Abundance and Citation Trustworthiness) are good but would like to see something similar and light weight also applied as live Eval’s specifically then measured against live research runs, against enterprise use cases.
So what changed in 2025? Two things. First, agentic workflows matured: vendors now provide end-to-end orchestration (search → triage → synthesis → QA), and many expose APIs that let you plug the agent into internal data and tooling via MCP:
Second, the depth of reasoning improved: LLM orchestration or an encompassing reasoning model moved from shallow aggregation to iterative reflection and retrieval loops, sometimes invoking dozens or hundreds of searches across a session. That made output richer, and longer, but also amplified risks of hallucination, bad citations and inaccuracies.
Where do we stand on enterprise readiness for producing thousands of deep research reports and providing business credibility, transparency and traceability?
- Closed-source, vendor-hosted agents or reasoning models tuned for Deep Research offer convenience and integrated guardrails, but they often hide intermediate reasoning and its currently harder to control the flow of tool calls with a reason model and prompting.
- The other option is open-source agentic workflows remain more auditable, you can inspect the state machine, instrument each step, and add bespoke QA steps, yet they require more engineering to hit the mark and you need to bake in the domain expertise and output quality.
- A nice and simple example provided by Google DeepMind Dev-Rel engineer: https://github.com/google-gemini/gemini-fullstack-langgraph-quickstart
There’s an argument for each going either way, it’s about balancing the current trade offs. One thing to note is a lot of the general knowledge will eventually end up in the reasoning model and the model will in essence eat away at the complicated workflow, simplifying the complexities into the model training itself.

What I worry about next is conflation: as models become better at doing the workflow by training on control flows, product teams may assume the agent’s internal choices are reliable. That’s convenient but It’s also a failure mode. When an agent collapses a chain of reasoning into a single confident paragraph, you need tooling and signals to detect missing steps, thin evidence, or inaccuracy failures.
Deep Research has matured into a viable product category thats fast, capable, and benchmark-driven, but it’s not yet a turnkey solution for enterprise report creation for every use case. The right approach is hybrid: let agents compress and structure work, then use humans and instrumentation to validate, contextualise, and decide.